I recently came across the joy of submitting an article to a journal for publication. I soon came to the conclusion that the process of submission is both exciting and stressful. Exciting because you realise that a piece of research is finally done but also stressful because you have to go through a check list and make sure your paper fits the journal’s guidelines.
Long story short, while doing this, one of the required fields of the journal was to propose three possible reviewers. As an early career researcher I do not exactly have a list of recommended reviewers up my sleeve. Thus there were only two things I could really do:
- Ask my co-authors for suggestions.
- Write a script.
I knew that contacting my co-authors would take some time, thus option 2 was selected.
From here onwards, I will be using the programming language Python to explain a
series of steps that I followed in order to choose my reviewers!
The first thing needed was a list of potential reviewers. This was easily retrieved
from the journal’s website, so I copied it and saved it as a txt file.
>>> with open('reviewers.txt', 'r') as textfile:
... names = textfile.read()
>>> names = names.split('\n')
>>> len(names)
1273As it can be seen, the number of suggested reviewers from the journal is 1273. That being a very large number of people to check manually, I needed to reduce the list based on the reviewers’ area of research. My second task was to collect data on my reviewers in order to gain insights in their research.
For my second task I will be using my open source project called Arcas, Arcas allows me to collect articles’ meta data by specifying just a single keyword.
Using the following few lines of code I am able to collect up to 100 articles that my reviewers have written and published in the journal Springer. Arcas allows you to ping 5 different sources but for the purpose of this work a single source, more specifically Springer works just fine.
>>> import pandas as pd
>>> import requests
>>> import arcas
>>> for p in [arcas.Springer]:
... for author in names:
... api = p()
... switch = True
... start = 1
... while switch is not False and start < 100:
... parameters = api.parameters_fix(author=author, records=10, start=start)
... url = api.create_url_search(parameters)
... request = api.make_request(url)
... root = api.get_root(request)
... raw_article = api.parse(root)
... try:
... articles = []
... for art in raw_article:
... articles.append(api.to_dataframe(art))
... df = pd.concat(articles, ignore_index=True)
... api.export(df, "{}_{}.json".format(author, start))
... except TypeError:
... switch=False
... start += 10Once the data has been collected I need to narrow down the reviewers that can understand the science of my work or its applications. For my third task I used the library pandas to check whether the keywords of my paper exist within any of the abstracts of my reviewers’ articles.
>>> keywords = ['keyword one', 'keyword two', 'keyword three']
>>> def find_reviewers(names, keywords):
... authors_with_no_articles = []
... authors_of_interest = []
... for name in names:
... try:
... df = read_author_files(name)
... df = df.dropna()
... for key in keywords:
... flag = check_keyword_in_abstract(key, df)
... if flag == True:
... authors_of_interest.append((name, key))
... except ValueError:
... authors_with_no_articles.append(name)
... return authors_of_interest, authors_with_no_articles
>>> keep, no_keep = find_reviewers(names, keywords)Finally, I can count the number of words each reviewer satisfied and plot a histogram! Thus the potential reviewers of my paper are the people who rank first on the following histogram.
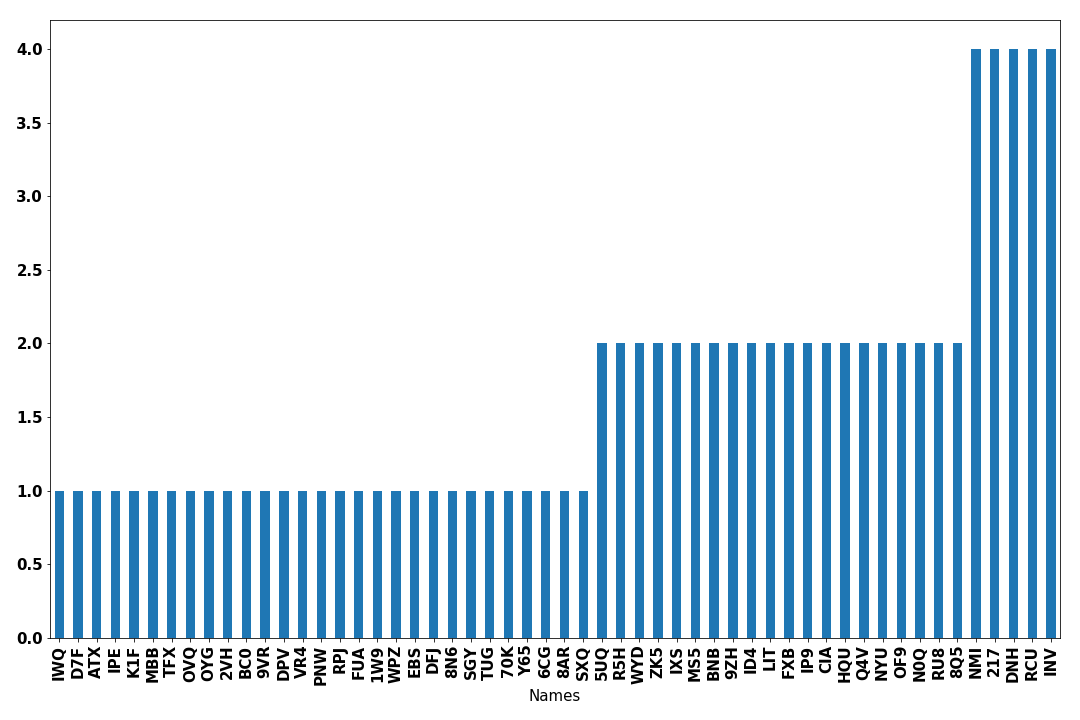
A manual check of the reviewers that stand out must be done as well. I am not implying that one should strictly follow the histogram but it was a fast and fun way of reducing a list of 1273 people down to 20.